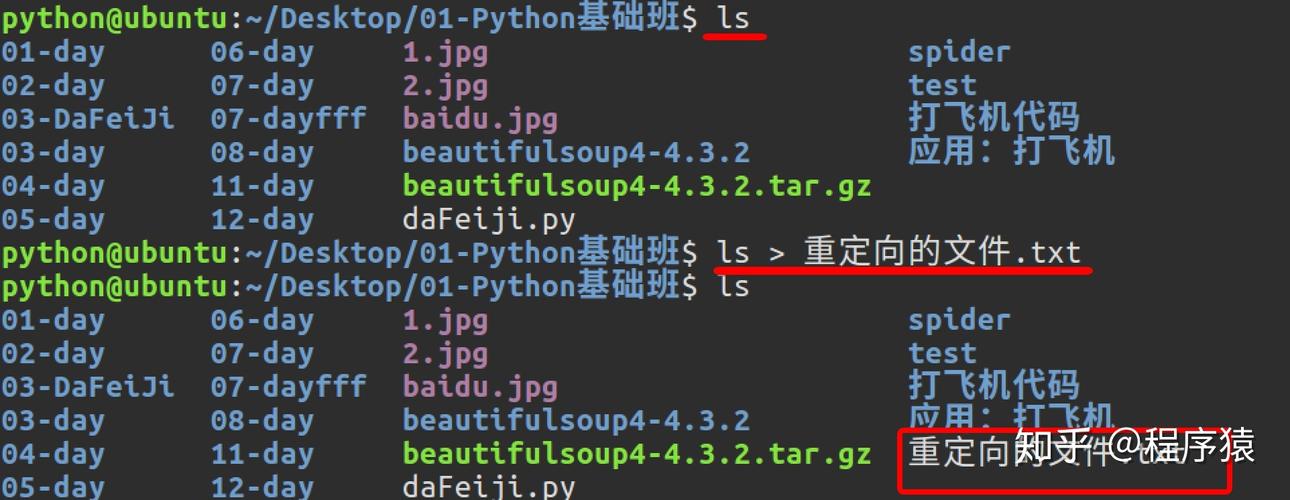
python 命令行输入
要在Python中通过命令行获取互联网上的最新内容,我们可以使用几种不同的方法,以下是一些常用的技术手段:
 (图片来源网络,侵删)
(图片来源网络,侵删)1、使用requests库进行HTTP请求
2、使用BeautifulSoup解析HTML内容
3、使用API(如果可用)
4、使用Web爬虫框架,如Scrapy
5、使用RSS阅读器获取更新
使用requests和BeautifulSoup获取网页内容
安装依赖
确保安装了requests和beautifulsoup4库,如果没有安装,可以使用pip安装:
pip install requests beautifulsoup4
代码实现步骤
1、导入所需模块。
2、使用requests.get()函数发起HTTP请求。
3、使用BeautifulSoup解析响应的HTML内容。
4、提取所需的最新内容。
示例代码
import requestsfrom bs4 import BeautifulSoup目标网页URLurl = 'https://example.com'发起GET请求response = requests.get(url)检查请求是否成功if response.status_code == 200: # 初始化BeautifulSoup对象并指定解析器 soup = BeautifulSoup(response.text, 'html.parser') # 提取最新内容,这取决于网站结构 # 以下是一个假设的例子,实际情况需要根据网站结构来定制选择器 latest_content = soup.find('div', class_='content').text print(latest_content)else: print("Failed to retrieve the webpage")使用API获取数据
许多网站提供API接口来获取最新的内容,这通常是最高效和最可靠的方法。
示例代码
import requestsAPI URLapi_url = 'https://api.example.com/latest'发起GET请求到APIresponse = requests.get(api_url)解析JSON响应if response.status_code == 200: data = response.json() latest_content = data['content'] print(latest_content)else: print("Failed to retrieve data from API")使用Web爬虫框架Scrapy
Scrapy是一个开源且强大的Python爬虫框架,用于从网站快速、高效地提取大量数据。
安装Scrapy
pip install scrapy
创建Scrapy项目
scrapy startproject tutorial
定义Item和Spider来抓取内容
在tutorial/items.py中定义数据项,并在tutorial/spiders/example_spider.py中编写爬虫逻辑。
使用RSS阅读器获取更新
很多网站提供RSS订阅服务,可以通过RSS阅读器或者直接解析RSS feed来获取最新内容。
示例代码
import feedparserRSS Feed URLfeed_url = 'https://example.com/rss'解析RSS feedfeed = feedparser.parse(feed_url)输出最新内容for entry in feed.entries: print(entry.title) print(entry.link) print(entry.published)
以上是几种在Python中通过命令行获取互联网上最新内容的常用方法,每种方法都有其适用场景,选择合适的方法可以有效获取需要的数据,在实际使用时,应当遵守网站的robots.txt规则,尊重版权和隐私,合理合法地进行数据抓取。
这篇流量运营《python 命令行输入》,目前已阅读次,本文来源于酷盾,在2024-04-10发布,该文旨在普及网站运营知识,如果你有任何疑问,请通过网站底部联系方式与我们取得联系