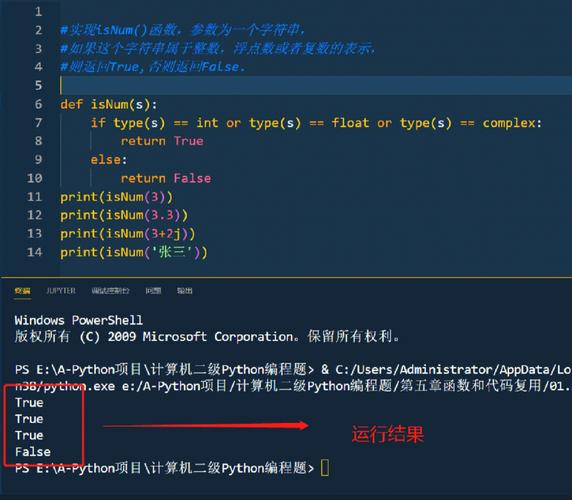
50道简单python函数题
要在Python中从互联网获取最新内容,通常需要使用Web爬虫(也称作网络爬虫或蜘蛛),Web爬虫是一种自动获取网页内容的程序,它可以从一个起始网页开始,通过抓取该网页上的所有链接来发现新的网页,然后继续这一过程,从而在互联网上“爬行”。
 (图片来源网络,侵删)
(图片来源网络,侵删)以下是编写一个基础的网络爬虫的步骤,以及如何将其用于获取最新内容的详细技术教学:
第一步:确定目标网站和数据
在开始编写爬虫之前,你需要明确以下几点:
1、你想要爬取哪个网站的数据。
2、你想要获取哪种类型的数据(新闻、博客文章、产品信息等)。
3、这些数据在网站中是如何组织的。
第二步:了解法律和伦理问题
在开始爬取任何网站之前,请确保你了解相关的法律和伦理问题,查看网站的robots.txt文件以了解网站允许爬虫爬取哪些内容,以及网站的使用条款和条件。
第三步:安装所需的库
为了方便地爬取网页,我们将使用requests库来发送HTTP请求,并使用BeautifulSoup库来解析HTML文档。
安装这些库的命令是:
pip install requests beautifulsoup4
第四步:发送HTTP请求
使用requests库,你可以发送一个HTTP GET请求到目标网站,并获取网页的内容。
import requestsurl = 'https://www.example.com'response = requests.get(url)确保请求成功response.raise_for_status()
第五步:解析HTML内容
一旦你获得了网页的HTML内容,你可以使用BeautifulSoup库来解析它,并提取你需要的数据。
from bs4 import BeautifulSoupsoup = BeautifulSoup(response.text, 'html.parser')假设你想要提取所有的新闻标题news_titles = soup.find_all('h2', class_='newstitle')for title in news_titles: print(title.text)第六步:存储或处理数据
根据你的需求,你可能想要存储这些数据到数据库、文件或者直接在程序中处理它们。
第七步:遵守礼貌政策
为了避免对目标网站的服务器造成不必要的负担,确保你的爬虫遵守礼貌政策,
在两次请求之间暂停一段时间。
不要模拟用户代理(UserAgent)字符串,除非你有合法的理由。
第八步:异常处理
添加异常处理来管理可能发生的错误,例如网络连接问题或页面结构变化。
第九步:测试和部署
在多个页面和不同的时间段测试你的爬虫,以确保它能够稳定运行,如果一切正常,你可以将其部署到服务器或云平台上,使其定时运行。
示例代码:
import timeimport requestsfrom bs4 import BeautifulSoupdef get_latest_content(url): try: response = requests.get(url) response.raise_for_status() except requests.RequestException as e: print(f"An error occurred: {e}") return None soup = BeautifulSoup(response.text, 'html.parser') news_titles = soup.find_all('h2', class_='newstitle') return news_titlesdef main(): url = 'https://www.example.com' latest_content = get_latest_content(url) if latest_content: for title in latest_content: print(title.text) else: print("No content found.")if __name__ == "__main__": main()这个例子是一个非常简单的爬虫,它只从一个固定的URL获取内容,在实际的应用中,你可能需要处理更复杂的情况,比如动态加载的内容、登录认证、爬取多个页面等。
记住,当你决定爬取一个网站时,始终要尊重该网站的爬虫政策,并确保你的活动是合法的。
这篇流量运营《50道简单python函数题》,目前已阅读次,本文来源于酷盾,在2024-04-07发布,该文旨在普及网站运营知识,如果你有任何疑问,请通过网站底部联系方式与我们取得联系