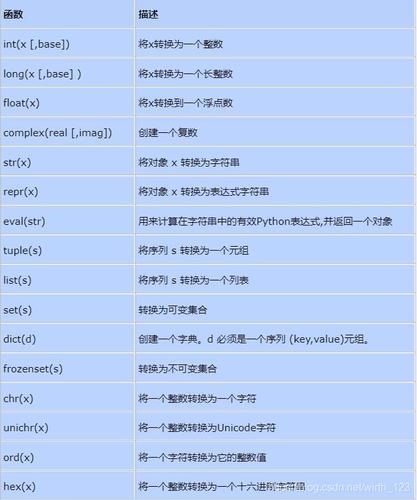
python函数的基本用法
在Python中,我们有多种方法可以从互联网获取最新内容,以下是一些常见的方法:
 (图片来源网络,侵删)
(图片来源网络,侵删)1、使用requests库获取网页内容
2、使用BeautifulSoup库解析网页内容
3、使用API获取特定网站或服务的最新内容
4、使用网络爬虫抓取网页内容
下面我们将详细讲解这些方法。
1. 使用requests库获取网页内容
requests库是Python中用于发送HTTP请求的库,可以用来获取网页内容,我们需要安装requests库,可以使用以下命令进行安装:
pip install requests
安装完成后,我们可以使用以下代码获取网页内容:
import requestsurl = 'https://www.example.com'response = requests.get(url)if response.status_code == 200: content = response.text print(content)else: print('请求失败,状态码:', response.status_code)2. 使用BeautifulSoup库解析网页内容
BeautifulSoup库是一个用于解析HTML和XML文档的库,可以用来提取网页中的特定内容,我们需要安装BeautifulSoup库,可以使用以下命令进行安装:
pip install beautifulsoup4
安装完成后,我们可以使用以下代码解析网页内容:
import requestsfrom bs4 import BeautifulSoupurl = 'https://www.example.com'response = requests.get(url)if response.status_code == 200: soup = BeautifulSoup(response.text, 'html.parser') title = soup.find('title').text print('网页标题:', title)else: print('请求失败,状态码:', response.status_code)3. 使用API获取特定网站或服务的最新内容
许多网站和服务提供了API接口,可以通过API接口获取最新内容,这里以获取GitHub上某个仓库的最新提交记录为例,我们需要安装requests库(如上文所述),然后使用以下代码获取最新提交记录:
import requestsowner = 'your_username'repo = 'your_repository'url = f'https://api.github.com/repos/{owner}/{repo}/commits'response = requests.get(url)if response.status_code == 200: commits = response.json() latest_commit = commits[0] print('最新提交信息:') print('提交者:', latest_commit['commit']['author']['name']) print('提交时间:', latest_commit['commit']['author']['date']) print('提交信息:', latest_commit['commit']['message'])else: print('请求失败,状态码:', response.status_code)4. 使用网络爬虫抓取网页内容
网络爬虫是一种自动访问网页并从中提取信息的程序,我们可以使用Python的Scrapy库来创建网络爬虫,我们需要安装Scrapy库,可以使用以下命令进行安装:
pip install scrapy
安装完成后,我们可以创建一个Scrapy项目,并在项目中定义一个Spider类来抓取网页内容,以下是一个简单的Scrapy爬虫示例:
1、创建Scrapy项目:
scrapy startproject myspider
2、在myspider/spiders目录下创建一个名为example_spider.py的文件,并添加以下代码:
import scrapyclass ExampleSpider(scrapy.Spider): name = 'example_spider' start_urls = ['https://www.example.com'] def parse(self, response): self.log('Visited %s' % response.url) for quote in response.css('div.quote'): item = { 'author_name': quote.css('span.text::text').extract_first(), 'author_url': quote.css('a::attr(href)').extract_first(), 'tags': quote.css('div.tags a.tag::text').extract(), } yield item next_page = response.css('li.next a::attr(href)').extract_first() if next_page is not None: yield response.follow(next_page, self.parse)3、运行爬虫:
scrapy crawl example_spider
以上示例展示了如何使用Scrapy库创建一个网络爬虫,从https://www.example.com网站抓取引用信息,具体的抓取规则需要根据目标网站的结构进行调整。
这篇流量运营《python函数的基本用法》,目前已阅读次,本文来源于酷盾,在2024-04-07发布,该文旨在普及网站运营知识,如果你有任何疑问,请通过网站底部联系方式与我们取得联系