python class调用函数
在Python中,我们可以使用类(class)来封装一些功能,当我们需要在互联网上获取最新内容时,可以创建一个类,然后在该类中定义一个函数来实现这个功能,接下来,我将详细介绍如何创建一个类并调用其中的函数来实现在互联网上获取最新内容的功能。
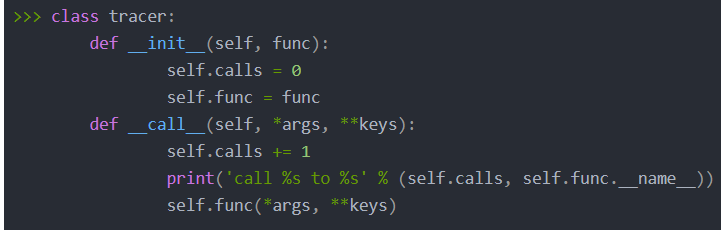
 (图片来源网络,侵删)
(图片来源网络,侵删)我们需要导入一些必要的库,如requests和BeautifulSoup。requests库用于发送HTTP请求,而BeautifulSoup库用于解析HTML文档,你可以使用以下命令安装这两个库:
pip install requestspip install beautifulsoup4
接下来,我们创建一个名为WebScraper的类,并在其中定义一个名为get_latest_content的函数,这个函数将接收一个URL作为参数,然后从该URL获取HTML文档,并解析出最新的内容,具体代码如下:
import requestsfrom bs4 import BeautifulSoupclass WebScraper: def get_latest_content(self, url): # 发送HTTP请求,获取HTML文档 response = requests.get(url) html_doc = response.text # 使用BeautifulSoup解析HTML文档 soup = BeautifulSoup(html_doc, 'html.parser') # 在这里,我们假设最新的内容位于一个具有特定ID的div元素中 # 你可以根据实际的HTML结构修改这部分代码 latest_content_div = soup.find('div', {'id': 'latestcontent'}) # 提取最新的内容 latest_content = latest_content_div.text return latest_content现在,我们已经创建了一个名为WebScraper的类,并在其中定义了一个名为get_latest_content的函数,接下来,我们可以创建一个WebScraper类的实例,并调用其get_latest_content函数来获取指定URL的最新内容,具体代码如下:
创建一个WebScraper类的实例scraper = WebScraper()指定要获取最新内容的URLurl = 'https://example.com'调用get_latest_content函数,获取最新内容latest_content = scraper.get_latest_content(url)打印最新内容print(latest_content)
请注意,上述代码中的HTML解析部分仅作为示例,实际上,你需要根据目标网站的HTML结构来修改这部分代码,以便正确地提取最新的内容,如果目标网站使用了反爬虫技术,你可能还需要添加一些额外的处理逻辑,如设置UserAgent、处理JavaScript等。
这篇流量运营《python class调用函数》,目前已阅读次,本文来源于酷盾,在2024-06-02发布,该文旨在普及网站运营知识,如果你有任何疑问,请通过网站底部联系方式与我们取得联系