python字符串数组
在Python中,字符串数组通常指的是一个包含多个字符串的列表,我们可以使用Python的各种库和功能来从互联网获取最新内容,并将其存储在字符串数组中,以下是详细的步骤和技术教学:
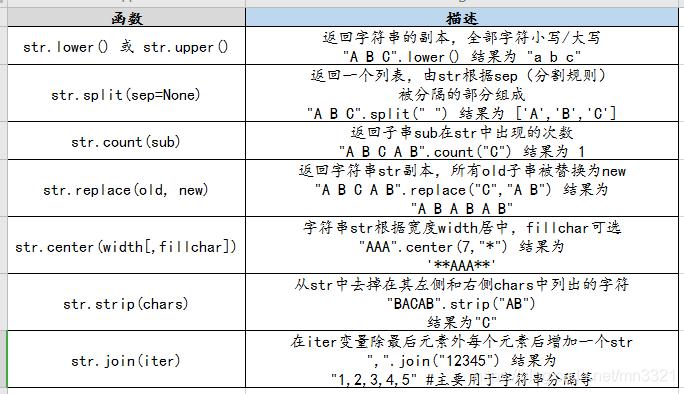
 (图片来源网络,侵删)
(图片来源网络,侵删)1、导入所需库
我们需要导入一些库来帮助我们完成任务,这些库包括requests(用于发送HTTP请求),BeautifulSoup(用于解析HTML文档)和re(用于正则表达式匹配)。
import requestsfrom bs4 import BeautifulSoupimport re
2、发送HTTP请求
我们需要向目标网站发送一个HTTP请求,以获取其HTML内容,我们可以使用requests库的get方法来实现这一点。
url = 'https://example.com' # 替换为你想要抓取的网站URLresponse = requests.get(url)html_content = response.text
3、解析HTML内容
接下来,我们需要使用BeautifulSoup库来解析HTML内容,这将使我们能够更容易地找到和提取所需的信息。
soup = BeautifulSoup(html_content, 'html.parser')
4、提取所需信息
现在我们需要从解析后的HTML内容中提取所需的信息,这通常涉及到查找特定的HTML标签、属性或文本,我们可以使用BeautifulSoup提供的方法来实现这一点。
如果我们想要提取所有段落文本,我们可以这样做:
paragraphs = soup.find_all('p')texts = [p.get_text() for p in paragraphs]5、将信息存储在字符串数组中
我们需要将提取到的信息存储在一个字符串数组中,这可以通过创建一个Python列表并将提取到的文本添加到列表中来实现。
string_array = texts
6、输出结果
我们可以打印字符串数组以查看结果。
print(string_array)
以下是完整的代码示例:
import requestsfrom bs4 import BeautifulSoupimport reurl = 'https://example.com' # 替换为你想要抓取的网站URLresponse = requests.get(url)html_content = response.textsoup = BeautifulSoup(html_content, 'html.parser')paragraphs = soup.find_all('p')texts = [p.get_text() for p in paragraphs]string_array = textsprint(string_array)请注意,这个示例仅适用于抓取静态网页,如果你需要抓取动态加载的内容,你可能需要使用其他库(如Selenium)来模拟浏览器行为,你可能需要根据目标网站的结构调整代码以正确提取所需信息。
这篇流量运营《python字符串数组》,目前已阅读次,本文来源于酷盾,在2024-05-12发布,该文旨在普及网站运营知识,如果你有任何疑问,请通过网站底部联系方式与我们取得联系